Дано:
При получении массива байт извне (например, через jni-буфер) необходимо преобразовать его в строку Java, с русскими буквами.
В чём сложность:
Символ "И" кодируется в
UTF-8 последовательностью из двух байтов:
0xD0,0x98. Соответственно, при чтении в кодировке
windows-1251 каждый из этих байтов декодируется по схеме данной кодировке. Так вот, я обнаружил следующее –
код 0x98 не определен в наборе символов windows-1251 и, соответственно, в схеме этой кодировки.
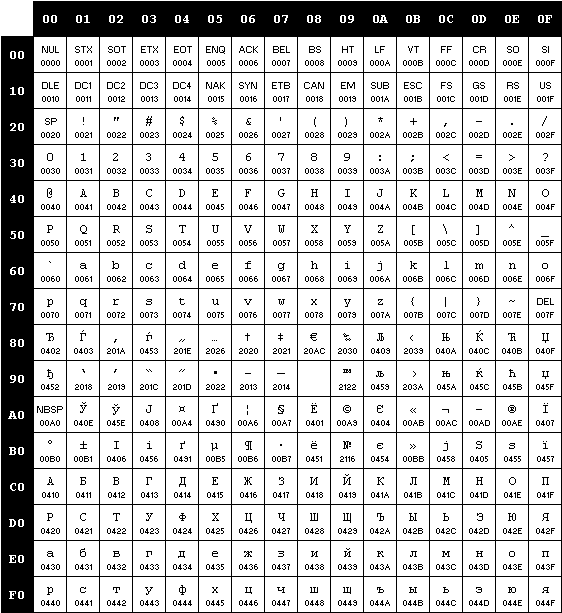
Вот схема кодировки cp1251, взятая с сайта Microsoft, а вот
ее описание (взято
отсюда). Как вы можете видеть, код
0x98 описан как
UNDEFINED.
Проблема и решение:
Допустим откуда-то извне к нам попал массив байт, с неизвестной кодировкой. И с этим массивом надо проделать некоторые преобразования, то возможен хитрый ньюанс. Если на входе кодировка UTF-8, а в массиве есть русская буква И, то при попытке в java-коде создать строку с кодировкой windows-1251, мы получим «?»(он же - неопределённый байт) в созданной строке. При дальнейшем преобразовании в байты, этот символ просто потеряется (зачем нужны такие преобразования, я тут рассматривать не буду, но иногда такие вещи случаются :-)).
Немного кода :
// получаем правильную последовательность байт (то, что пришло нам извне)
byte[] bytes = «И-диотизм».getBytes("UTF-8");
// Создаём строку с кодировкой по умолчанию
// Напечатает «Каракули=Р?-диотизм», где видно, что один символ «?»
System.out.println("Каракули=" + new String(bytes, "Cp1251"));
System.out.println("Каракули=" + new String(bytes)); // аналогично
// Дальнейшее преобразование и потеря информации
String s1251_x = new String(bytes);
String xx = new String(s1251_x.getBytes(), "UTF-8"); // даже в изначально правильной кодировке
// Выведет «xx=??-диотизм,len=10»
System.out.println("xx=" + xx + ",len=" + xx.getBytes().length);
Решение :
Единственное решение, которое (на данный момент) я знаю, это узнавать в каждом конкретном случае какая кодировка приходит на вход и создавать первую строку в соответствующей кодировке.
// Если сразу сделать так
String sUtf8 = new String(bytes, "UTF-8");
// то и дальнейшие преобразования не потеряют информацию на входе
// Напечатает «sUtf8=И-диотизм,len=17»
System.out.println("sUtf8=" + sUtf8 + ",len=" + bytes.length);
String s1251_2 = new String(sUtf8.getBytes(), "Cp1251");
// Напечатает «s1251_2=И-диотизм»
System.out.println("s1251_2=" + s1251_2);
P.S.: Я эти заметки пишу для себя, и для конкретной ситуации, которая случилась в нашем коде. О глобальном подходе к кодированию/декодированию очень понятно и хорошо написано тут :
http://www.skipy.ru/technics/encodings.html
{kind=link}